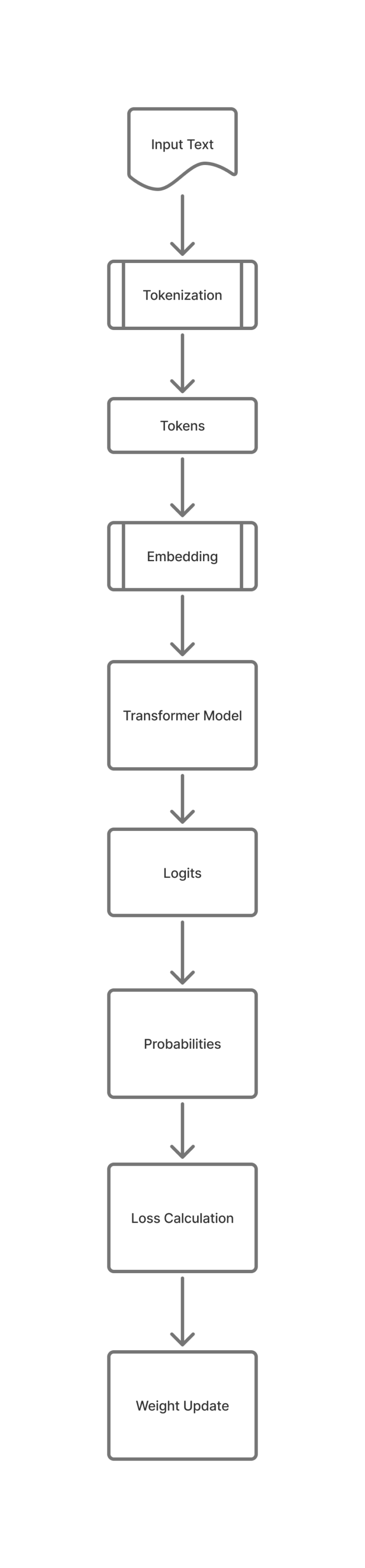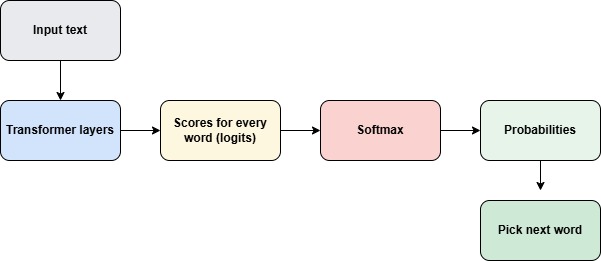
When LLM predict the next word, it first gives scores for every possible words from the transformer stage of LLM.
I like to drink __________
The model produces scores for words like
| Word | Score |
|---|---|
| tea | 5.2 |
| coffee | 4.8 |
| water | 3.1 |
| car | -1.5 |
These numbers are called logits. But these are scores and not probabilities. The scores of words does not sum up to 1.
Softmax is a fucntion which converts these scores to probabilites.
Softmax function formula.
Softmax takes the scores and turns them into probabilities like this:
| Word | Probability |
|---|---|
| tea | 0.52 |
| coffee | 0.36 |
| water | 0.11 |
| car | 0.01 |
Here if you see the sum of all probabilities add up to 1. It made the score as positive also.
Now the model can choose the next word to be given as output.
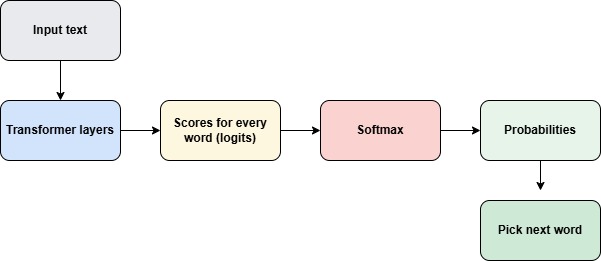
So softmax converts the model’s raw scores into probabilities so the LLM can choose the next word.