Artificial Intelligence
Understanding Pre-Training in Large Language Models
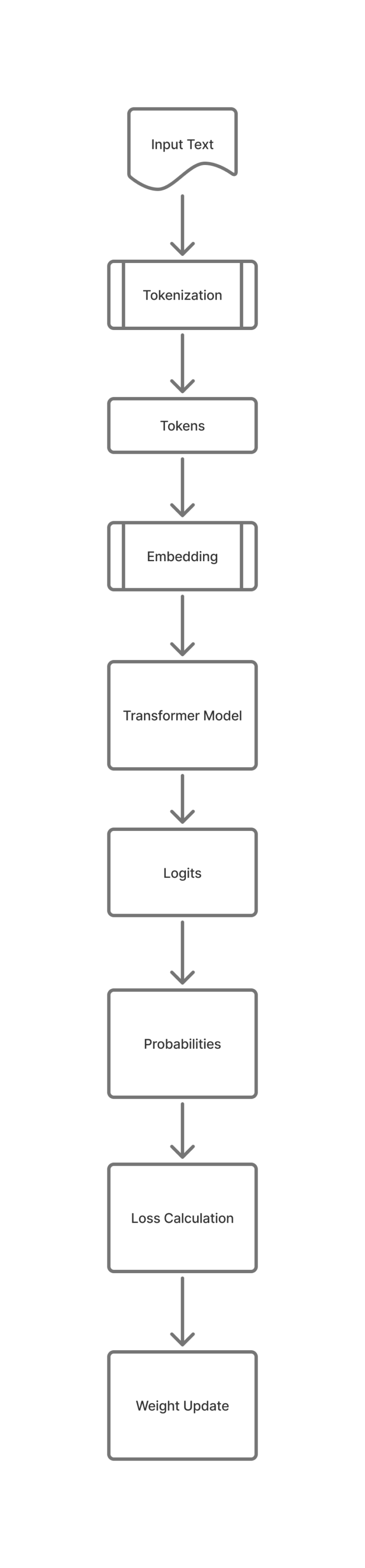
Pre-training is the phase where we teach a model how language works. Before a model can answer questions,...
Pre-training is the phase where we teach a model how language works. Before a model can answer questions,...
AI application now a days are not only generating texts , but also images, audio and videos. The...
A token is a piece of text the model understands. It may be: Now each token will have...
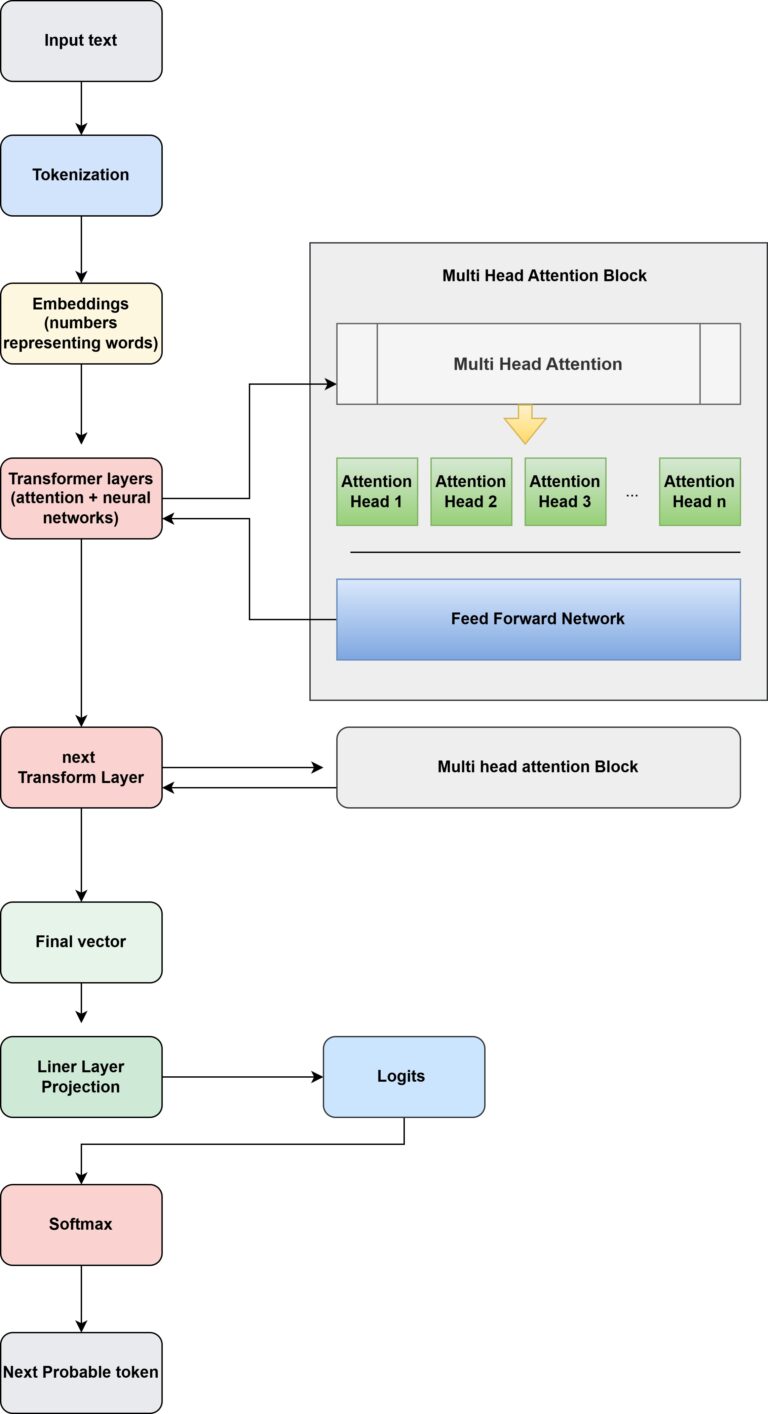
The attention heads live inside the Transformer layer Each Transformer layer actually contains two main parts: 1 Multi-Head...
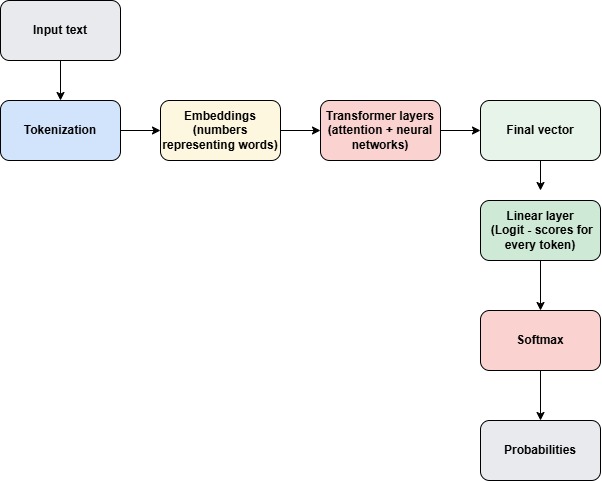
The model scores (logits) come from the last neural network layer of the transformer. After many transformer layers,...
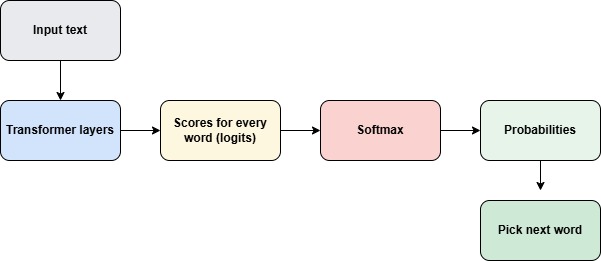
When LLM predict the next word, it first gives scores for every possible words from the transformer stage...
In the simplest terms, an Epoch represents one complete pass of your entire training dataset through the the...
Local LLMs (Large Language Models) are changing the game for developers, writers, and privacy advocates. Running a model...
Lets start with Q4_K_M. An example of it is mistralai/mistral-7b-instruct-v0.3 Lets go through each parameters, Q4 Means 4-bit...
Here you can get the details about the new regime income tax slab rates for FY 2025-26 (Assessment...