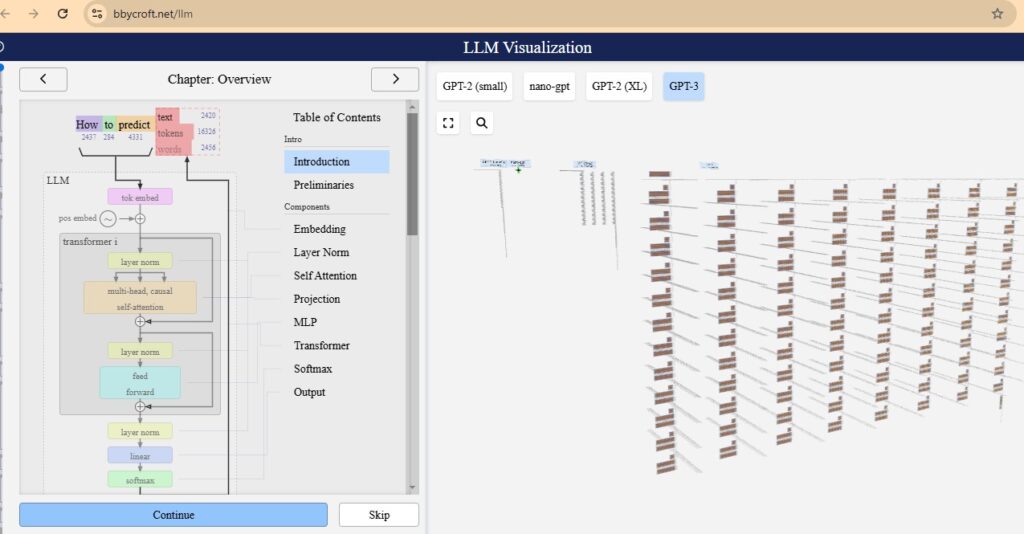
Have you seen the LLM working internally? Recently I came across this site where the enter flow of LLM can be visualized. Please check the below link https://bbycroft.net/llm
Transformer-based LLM Architecture (Components)
- Embedding
- Layer Normalization
- Self-Attention
- Projection
- Feed Forward Network (MLP)
- Transformer Block
- Softmax and Output
Large Language Models (LLMs) such as GPT and BERT are based on the Transformer architecture, which processes sequences of tokens using attention mechanisms instead of traditional recurrent or convolutional structures. This design enables efficient parallelization and long-range dependency handling.
As preliminary, a sequence of input tokens (words, subwords, or characters) is first converted into numerical representations before entering the Transformer.
Key terms:
- Token embedding (tok embed): Converts tokens into dense vectors.
- Positional embedding (pos embed): Adds position information to each token to preserve sequence order.
- Layer normalization (layer norm): Stabilizes and speeds up training by normalizing input features.
1. Embedding
Each input token is transformed into a token embedding vector. Since the Transformer has no inherent notion of sequence order, a positional embedding is added to encode word order:
Ei=TokenEmbedding(wi)+PositionalEmbedding(i)E_i = \text{TokenEmbedding}(w_i) + \text{PositionalEmbedding}(i)Ei=TokenEmbedding(wi)+PositionalEmbedding(i)
2. Layer Normalization
Layer normalization is applied before or after key operations (depending on implementation). It ensures stable gradients and helps the model converge faster.
3. Self-Attention
The multi-head, causal self-attention mechanism allows each token to attend to previous tokens (causal masking ensures autoregressive behavior).
Steps:
- Compute queries (Q), keys (K), and values (V) from embeddings.
- Calculate attention scores
4. Projection
After self-attention, the outputs from all heads are concatenated and passed through a linear projection layer to mix the information.
5. Feed Forward Network (MLP)
Each token’s representation is passed through a position-wise feed-forward network (two linear layers) with a non-linear activation such as GELU or ReLU
6. Transformer Block
Each Transformer layer (or block) includes:
- Layer Norm → Multi-Head Self-Attention → Residual Connection
- Layer Norm → Feed Forward → Residual Connection
Multiple Transformer layers are stacked to form the LLM backbone.
7. Softmax and Output
After the final Transformer layer:
- A layer norm is applied.
- The result is passed through a linear layer projecting to vocabulary size.
- Softmax converts logits into probability distributions over the vocabulary.
This output determines the next token prediction.
Summary
| Component | Function |
|---|---|
| Token Embedding | Converts words into dense vectors |
| Positional Embedding | Adds sequence order information |
| Layer Norm | Stabilizes model training |
| Self-Attention | Enables context understanding |
| Feed Forward | Expands representational capacity |
| Transformer Layers | Stack of attention + feed forward blocks |
| Linear + Softmax | Produces final token probabilities |