- Python installation in Windows
 https://www.python.org/ftp/python/pymanager/python-manager-26.2.msix From Windows PowerShell please see python –versionPython 3.14.5 Now in VS Code or bash terminal in Windows please do Now let create a virtual environment $ python -m venv .venv $ source .venv/Scripts/activate(.venv)
https://www.python.org/ftp/python/pymanager/python-manager-26.2.msix From Windows PowerShell please see python –versionPython 3.14.5 Now in VS Code or bash terminal in Windows please do Now let create a virtual environment $ python -m venv .venv $ source .venv/Scripts/activate(.venv) - How Antropic Internal Code Leaked via the Public npm Registry ?
 So, you’ve probably seen the news about the internal code exposure. It sounds like a sophisticated breach, but in reality, it was a classic DevOps nightmare involving a simple misconfiguration in the CI/CD pipeline. Let see what have happend. If you are familiar with npm (Node Package Manager), you know that the package.json is the… Read more: How Antropic Internal Code Leaked via the Public npm Registry ?
So, you’ve probably seen the news about the internal code exposure. It sounds like a sophisticated breach, but in reality, it was a classic DevOps nightmare involving a simple misconfiguration in the CI/CD pipeline. Let see what have happend. If you are familiar with npm (Node Package Manager), you know that the package.json is the… Read more: How Antropic Internal Code Leaked via the Public npm Registry ? - Understanding Pre-Training in Large Language Models
 Pre-training is the phase where we teach a model how language works. Before a model can answer questions, write code, or chat with us, it needs to learn the structure and patterns of language. This learning happens during pre-training. From Text to Tokens Everything begins with raw text. For example: “The cat sat on the… Read more: Understanding Pre-Training in Large Language Models
Pre-training is the phase where we teach a model how language works. Before a model can answer questions, write code, or chat with us, it needs to learn the structure and patterns of language. This learning happens during pre-training. From Text to Tokens Everything begins with raw text. For example: “The cat sat on the… Read more: Understanding Pre-Training in Large Language Models - An Introduction to Vision Language ModelAI application now a days are not only generating texts , but also images, audio and videos. The similar approach of transformer architecture is used in Vision language model also. We will see the comparison first. Here image patch is just a small square chunk of an image. Now a small chunk here is having… Read more: An Introduction to Vision Language Model
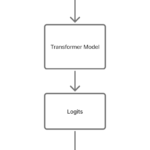
- Tokens and logits relation in LLMA token is a piece of text the model understands. It may be: Now each token will have a specific numerical value assigned. Token Token ID I 40 love 3047 machine 7342 learning 7524 Above is take from gptforworks website. Each LLM has its own tokenizer and token IDs. Where Logits Come In, Logits =… Read more: Tokens and logits relation in LLM