A token is a piece of text the model understands. It may be:
- a word
- part of a word
- punctuation
- space
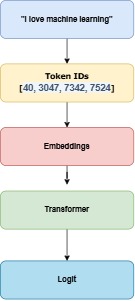
Now each token will have a specific numerical value assigned.
| Token | Token ID |
|---|---|
| I | 40 |
| love | 3047 |
| machine | 7342 |
| learning | 7524 |


Above is take from gptforworks website.
Each LLM has its own tokenizer and token IDs.
Where Logits Come In,
Logits = raw scores for every possible next token.
Related post – How LLM is predicting the next token and what is softmax?