The model scores (logits) come from the last neural network layer of the transformer.
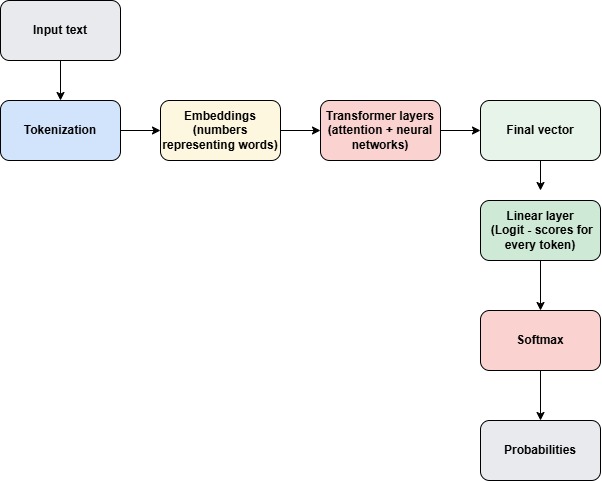
After many transformer layers, the model produces a vector that represents the context of the sentence.
“The sky is”
↓
Context vector
[0.23, -1.2, 0.88, 2.1, …]
Linear layer converts the vector to scores.
Think of it as a huge table of weights that converts the vector into a score for every token in the vocabulary.
If the vocabulary has 50,000 tokens, the model produces 50,000 scores.
Example output:
| Token | Score |
|---|---|
| blue | 8.3 |
| green | 2.1 |
| cloudy | 3.5 |
| car | -4.0 |
These are the logits.
Now let use see in a very abstract way how the score is produced,
The score came from a Neural Network Equation
scores = hidden_state × weight_matrix + bias- hidden_state → vector from transformer
- weight_matrix → learned during training
- bias → small adjustment
During training, the model learns weights that make the correct next token get the highest score.
So in summary the scores come from the final linear layer of the transformer, which converts the sentence’s internal representation into a score for every token in the vocabulary.
Related post – How LLM is predicting the next token and what is softmax?