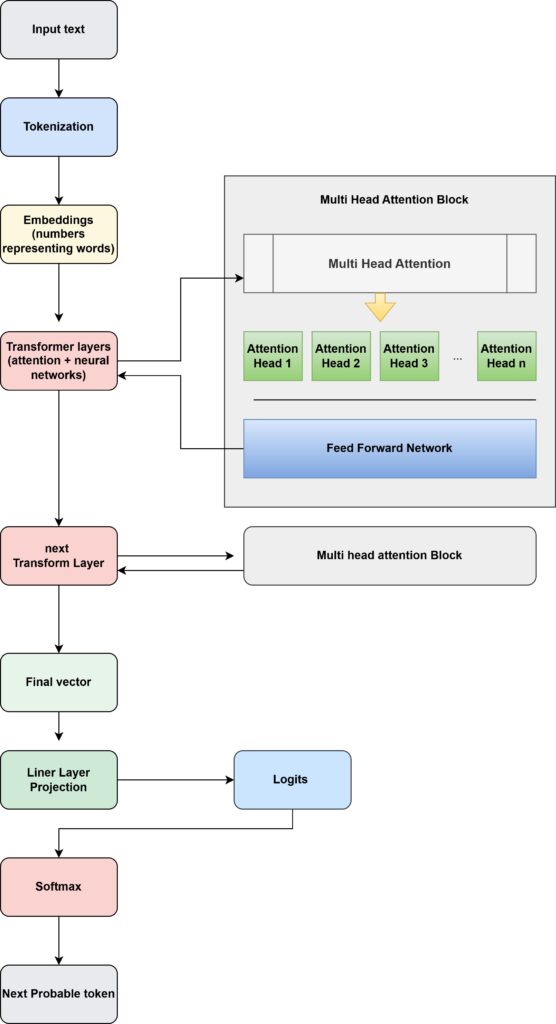
The attention heads live inside the Transformer layer
Each Transformer layer actually contains two main parts:
1 Multi-Head Self Attention
2 Feed Forward Neural Network
Attention heads operate inside each transformer layer to determine how tokens in the sentence relate to each other before the model predicts the next token.
Related post – How LLM is predicting the next token and what is softmax?