Pre-training is the phase where we teach a model how language works.
Before a model can answer questions, write code, or chat with us, it needs to learn the structure and patterns of language. This learning happens during pre-training.
From Text to Tokens
Everything begins with raw text.
For example:
“The cat sat on the mat”
A model cannot understand text directly. So the first step is to convert text into tokens.
Tokens are smaller units of text. They may look like words, subwords, or even characters depending on the tokenizer.
So the sentence becomes something like:
[“The”, “cat”, “sat”, “on”, “the”, “mat”]
This process is called tokenization.
One common method used for tokenization is
Byte Pair Encoding.
Instead of splitting text only into words or characters, BPE creates subword tokens.
Let’s understand with an example:
Words:
- low
- lowest
- new
- newer
Step 1: Break into characters
l o w
l o w e s t
n e w
n e w e r
Step 2: Find the most frequent pair
For example: “l” + “o” → “lo”
Step 3: Merge it
Now we get:
lo w
lo w e s t
Step 4: Repeat
Eventually, we get useful tokens like:
“low”, “est”, “new”, “er”
So instead of storing every possible word, the model learns reusable building blocks.
Each model is trained with a specific tokenizer.
To find it, you can:
- Check the model card
- Read official documentation
- Look at repositories (like Hugging Face Transformers)
Some common patterns:
- Files like
merges.txt→ BPE .modelfiles → SentencePiecevocab.txt→ WordPiece
After tokenization, each token is converted into a token ID.
Example:
“cat” → 345
This is just a number used as an index.
Important point:
A token ID does NOT carry meaning.
It is only a reference.
Now comes the key step.
Each token ID is mapped to a vector using an
embedding matrix.
So instead of:
cat → 345
We get:
cat → [0.55, 0.12, -0.44, …]
This list of numbers is called an embedding.
Why not represent a word with just one number?
Because a single number cannot capture meaning.
With multiple numbers (a vector), the model can:
- Represent different features
- Compare similarity between words
- Learn relationships
For example:
- “cat” and “dog” will have similar vectors
- “cat” and “car” will be far apart
This is known as a distributed representation.
Vectors allow the model to understand relationships.
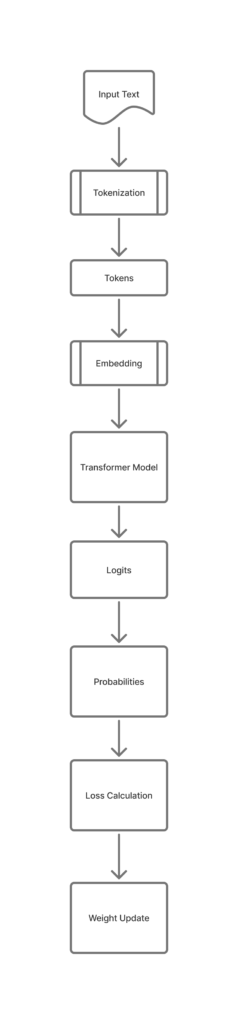
What Happens During Pre-Training?
Now we connect everything.
The flow looks like this:
Text → Tokens → Token IDs → Embeddings → Model → Prediction
The model is trained to predict the next token.
Example:
“The cat sat on the ___”
The model tries to predict:
“mat”
It produces scores (called logits), converts them to probabilities, and compares with the correct answer.
Then it updates its internal values using
backpropagation.
This process repeats billions of times.