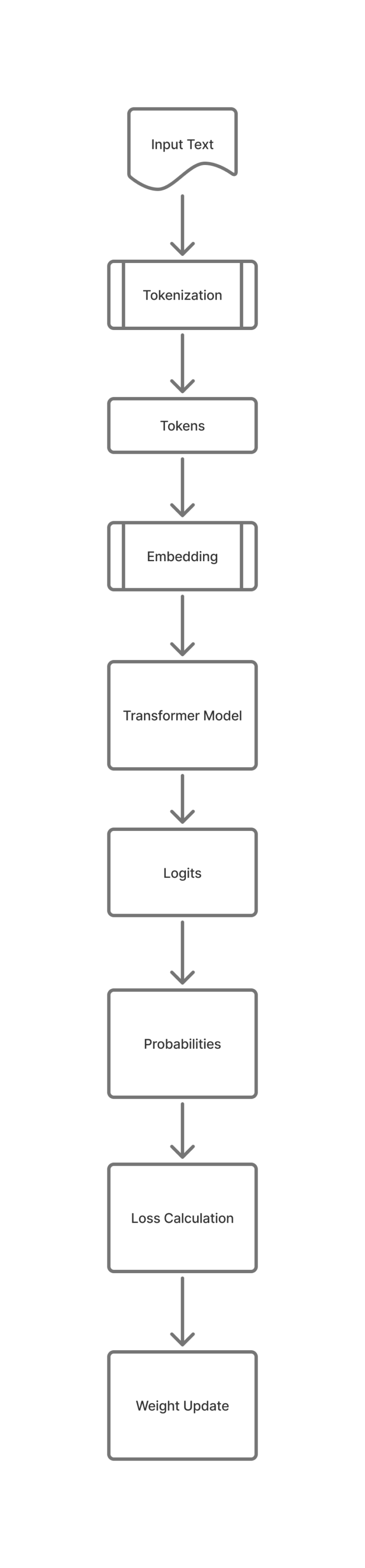
AI application now a days are not only generating texts , but also images, audio and videos.
The similar approach of transformer architecture is used in Vision language model also. We will see the comparison first.
Here image patch is just a small square chunk of an image. Now a small chunk here is having image pixels.
As you know pixel are basically having RGB ( Red , Green and Blue) values.
Lets try to understand the journey from patch to embedding in very simple and understandable way.
As we said patch is just a square pice of an image. Consider we have 4 * 4 patch portions of an image.
For a 4 * 4 patch, it will have 4*4*3 = 48 numbers.
Now a patch is flatten . Ie take a 3D block and write all numbers in a single list (row)
As an example, let take a small patch as
2 × 2 patch (RGB) . Each pixel 3 values , Red , Green and Blue – (RBG).
So here there will be 4 pixels in a patch and 4 * 3 = 12 numbers
Now the a single patch will look like
[ pixel1 , pixel2, pixel3 pixel4 ]
[ ( R1 , G1 , B1 ) , ( R2 , G2 , B2 ), ( R3 , G3 , B3 ), ( R4 , G4 , B4 ) ]
so after flattening , the above 3D vector becomes
[ R1, G1, B1, R2, G2, B2, R3, G3, B3, R4, G4, B4 ].
This vector just contain just raw pixel intensities. The values don’t have any meaning yet.
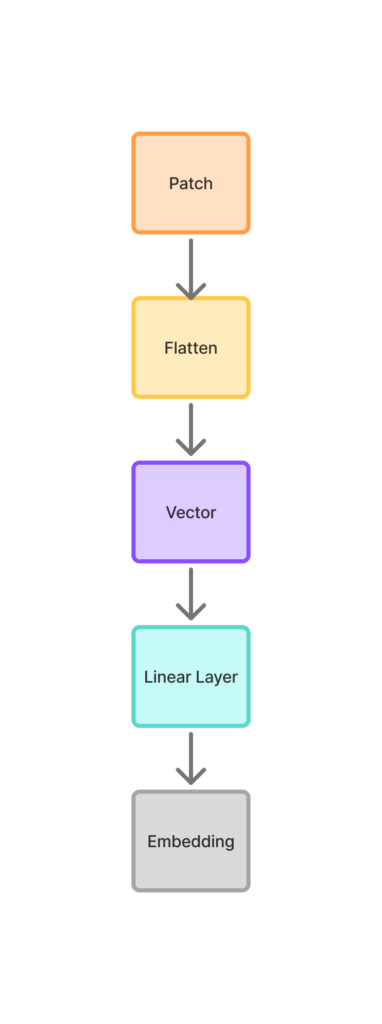
Now we will apply neural transformation on the vector (Linear Layer). Once you do it , you will learn about edges textures colors patterns , which is basically feature extraction.
Here is where “learning” actually begins.
On the above linear layer, once the neural transformation is applied , it becomes an embedding, which is patch embedding.
Now this behave like a token.
In text based LLM, we get the token ID from vocabulary.
Related post – How LLM is predicting the next token and what is softmax?